

Okay, so you want to extract just the text from a website because you don’t know how, right? Maybe you want to use this in your favorite AI like ChatGPT or Claude.ai. For this, there are several approaches you can use for extracting clean text from any website. How easy this is ultimately depends on how technical you are. Or you can use a tool like URLtoText.com to do it super easily.
The easiest option is to just use our free tool URLtoText!👇
Contents
Here are the three approaches you can use:
- Use “save as” in your browser and then input into AI to clean it up.
- Write a Python script.
- EASY: Use a FREE tool like: URLtoText.com
Okay, now let’s get into the details of how you can use each of these options.
1. Save as Text and Use AI
This method involves saving the entire webpage as a text file and then using an AI tool to extract the relevant content.
1. Save the webpage: Use your browser’s “Save As” function and choose “Text Files” or “Web Page, Text Only” as the file type.
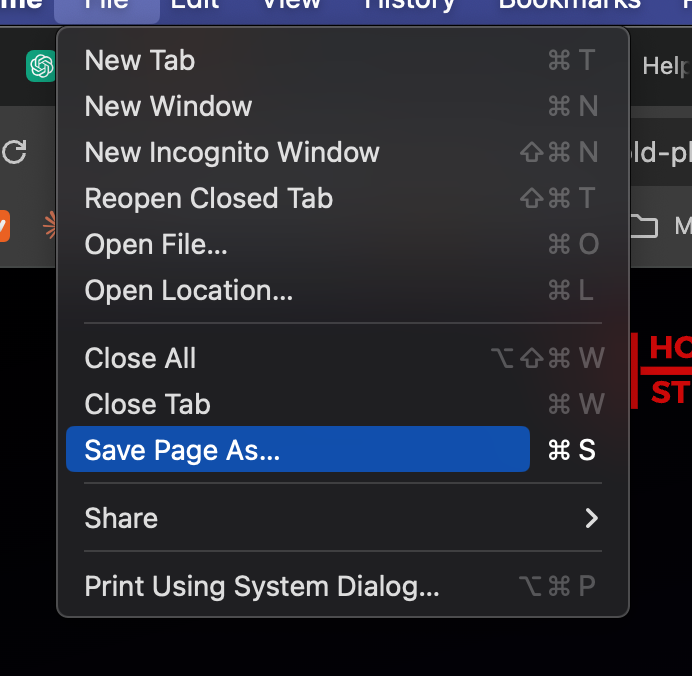
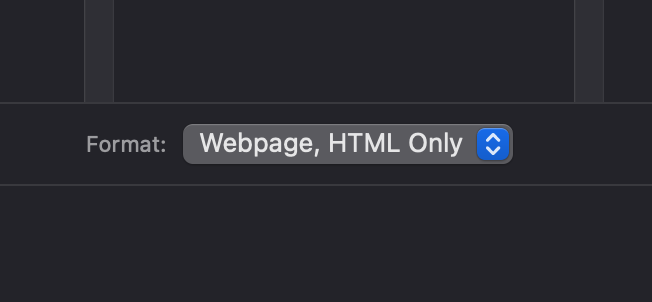
Open the saved file: You’ll notice it contains all the HTML along with the text.
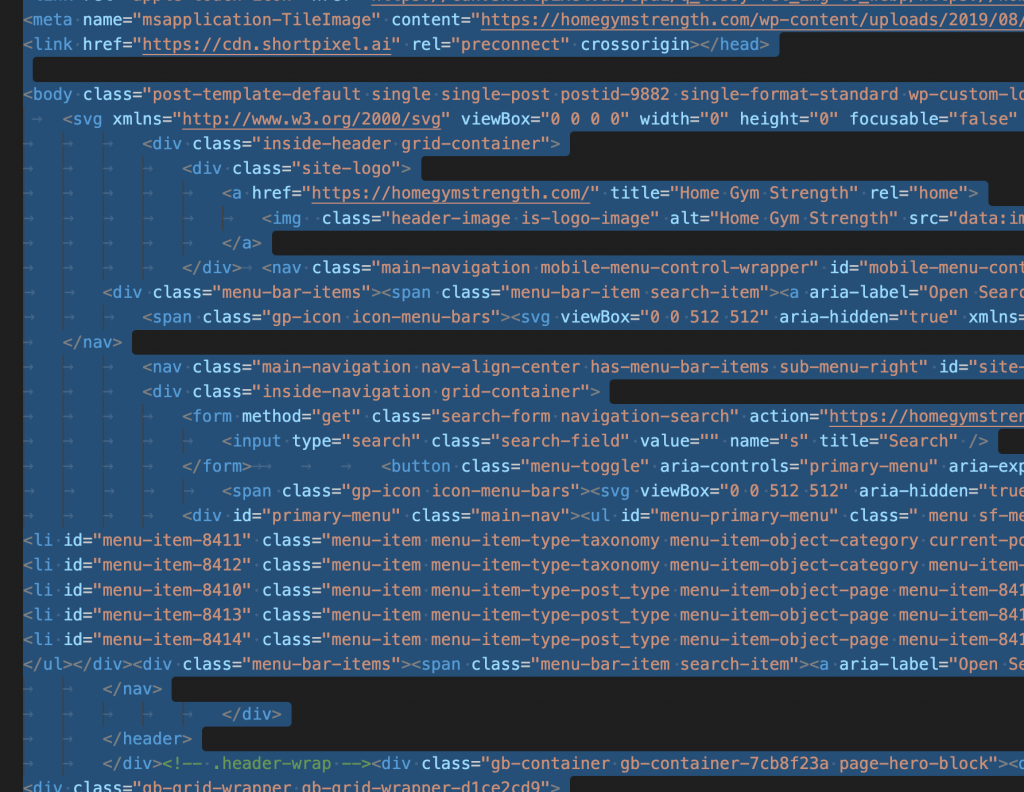
Use an AI tool: Copy the contents of the file and paste them into an AI tool like Claude.ai or ChatGPT.
Request extraction: Ask the AI to give you back just the raw text.
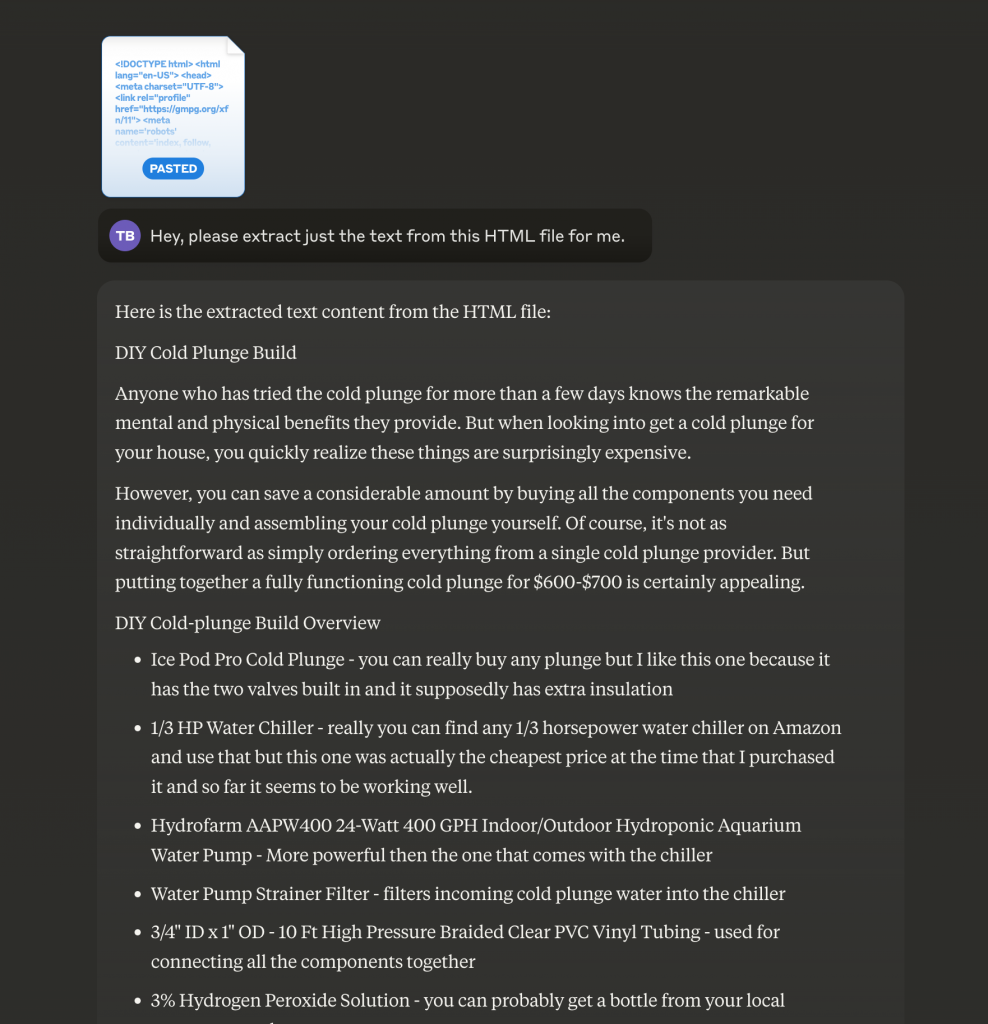
Note: This method works as long as the HTML is not too big. Unfortunately, for many websites, the HTML content may be too large for this approach to be practical.
2. Python Script with BeautifulSoup
For a more programmatic and scalable approach, you can use Python with the BeautifulSoup library to extract text from websites.
1. install the required libraries
pip install requests beautifulsoup42. Create a Python script:
import requests
from bs4 import BeautifulSoup
def extract_text(url):
# Fetch the webpage content
response = requests.get(url)
# Parse the HTML content
soup = BeautifulSoup(response.text, 'html.parser')
# Extract text from all paragraph tags
paragraphs = soup.find_all('p')
text = ' '.join([p.get_text() for p in paragraphs])
return text
# Example usage
url = 'https://example.com'
extracted_text = extract_text(url)
print(extracted_text)Run the script, replacing the URL with the desired webpage.
This method gives you more control over the extraction process and can be customized to target specific HTML elements.
3. Use urltotext.com (Easiest Option)
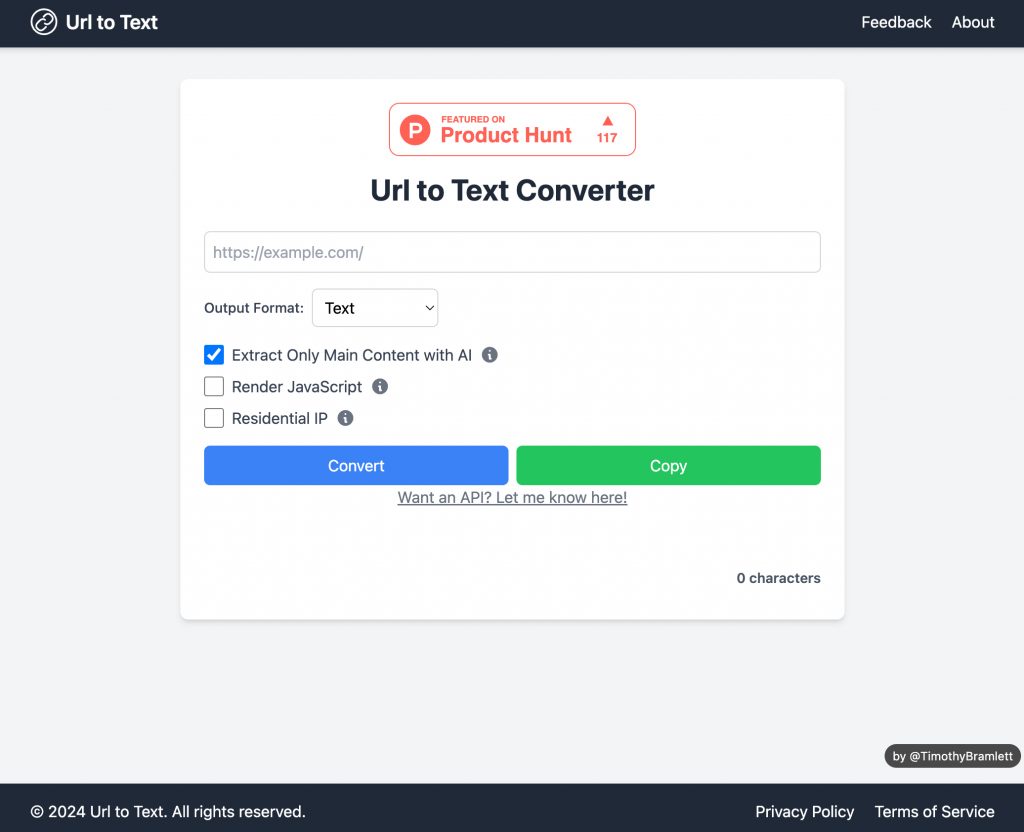
The easiest and most efficient method is to use the urltotext.com platform. This purpose-built tool simplifies the process of extracting text from websites.
- Visit urltotext.com
- Enter the URL of the webpage you want to extract text from
- Choose your preferred output format (plain text or Markdown)
- Click the extract button
Using urltotext.com offers several advantages:
- No coding required
- Handles complex website structures
- Option to extract as Markdown, preserving some formatting
- Fast and reliable results
This platform allows you to extract content as Markdown as well, which is a good option for preserving basic formatting while still getting clean, readable text.
Frequently Asked Questions (FAQ)
Q: Why would I need to extract just the text from a website?
A: Text extraction is useful for content analysis, data mining, creating summaries, or simply reading content without distractions.
Q: Can I extract text from websites that require login?
A: Most basic extraction methods won’t work with login-protected content. You might need more advanced techniques or API access for such cases.
Q: How accurate is the text extraction process?
A: Accuracy varies depending on the method and the website’s structure. Purpose-built tools like urltotext.com generally provide the best results.
Q: Will extracting text preserve the original formatting?
A: Plain text extraction typically removes most formatting. However, extracting as Markdown (available on urltotext.com) can preserve some basic formatting elements.
Q: Is it legal to extract text from any website?
A: While extracting text for personal use is generally acceptable, always check the website’s terms of service. Some sites prohibit scraping or bulk extraction of content.
Q: Can I extract text from PDFs or other document types hosted on websites?
A: The methods described here are primarily for web pages. Extracting text from PDFs or other document types may require different tools or approaches.
Q: How can I handle websites in languages other than English?
A: Most extraction methods work regardless of language. However, ensure your tools support Unicode for proper handling of non-Latin characters.
Q: How can I extract text from multiple web pages at once?
A: While most methods require you to process URLs one at a time, urltotext.com is planning to support multiple URLs soon. If you’re interested in this feature, email support@urltotext.com to express your interest and stay updated.
Q: What if the website’s content is dynamically loaded using JavaScript?
A: For dynamically loaded content, urltotext.com offers a “Render JavaScript” option. By checking this box during the extraction process, you can ensure that JavaScript-loaded content is captured.
Q: How do I handle websites that use CAPTCHA or other anti-scraping measures?
A: Urltotext.com has a solution for this. They offer a “Use residential proxy” option that can bypass CAPTCHAs and other anti-scraping measures. Simply check this box when extracting text from protected websites.
Q: Is it possible to preserve images or other media when extracting text?
A: Currently, most text extraction methods, including urltotext.com, focus solely on text content. However, urltotext.com is considering adding support for preserving images and other media in the future. If you’re interested in this feature, you can email support@urltotext.com to express your interest.