
Web scraping might seem straightforward at first glance, but as many developers quickly discover, what starts as a simple data extraction task can rapidly evolve into a complex technical challenge. While basic scraping scripts are easy to write, scaling them for production use reveals a host of obstacles that can derail your project.
The Deceptively Simple Start
Getting started with web scraping appears remarkably easy. A basic Python script requires just a few lines of code and two popular libraries: requests and Beautiful Soup. Here’s how simple it looks initially:
import requests
from bs4 import BeautifulSoup
# Hardcoded URL for text extraction
url = "https://httpbin.org/html"
# Make HTTP request to the URL
response = requests.get(url)
# Parse the HTML content using BeautifulSoup
soup = BeautifulSoup(response.content, 'html.parser')
# Extract all text content
text_content = soup.get_text()
# Print the extracted text
print(text_content)The process follows a straightforward pattern. First, you define the URL you want to scrape as a string variable. Next, you use the requests library to fetch the webpage content from that URL. Then you pass the resulting HTML through Beautiful Soup’s parser, storing the parsed content in a variable. Finally, you extract clean text using Beautiful Soup’s get_text() method and display the results.
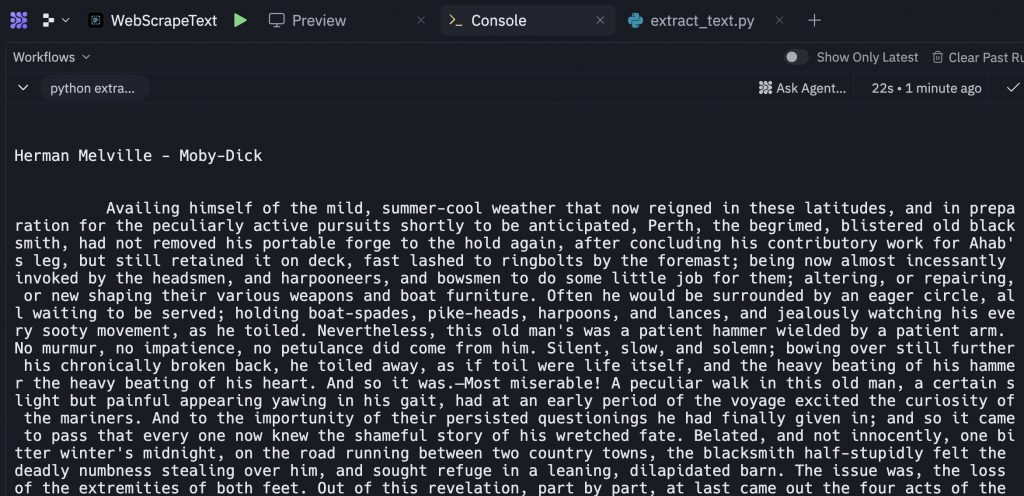
When you run this script against a simple website, it works beautifully. Clean, readable text appears in your console, and you might think web scraping is solved. However, this initial success is misleading because the test website lacks the protective measures that real-world sites employ.
The Reality of Production Web Scraping
The script above works only because it targets a website with no scraping protections. Production websites tell a very different story. Modern sites deploy sophisticated anti-scraping technologies that can quickly render your simple script useless.
JavaScript Rendering Challenges

One of the first major obstacles you’ll encounter is JavaScript-dependent content. Many modern websites generate their content dynamically using JavaScript frameworks like React, Angular, or Vue.js. Your basic requests and Beautiful Soup combination cannot execute JavaScript, meaning you’ll only capture the initial HTML shell without any of the dynamically loaded content.

To handle JavaScript rendering, you need to implement a headless browser solution. This typically involves setting up tools like Selenium to drive browsers like Chrome or Firefox in headless mode. The complexity increases dramatically as you now need to manage browser instances, handle timing issues for content loading, and deal with significantly higher resource consumption.
Anti-Scraping Technologies
Real websites don’t just passively serve content to any requester. They actively employ various technologies to identify and block automated scraping attempts. These protections can include rate limiting, CAPTCHA challenges, device fingerprinting, and behavioral analysis that detects non-human traffic patterns.
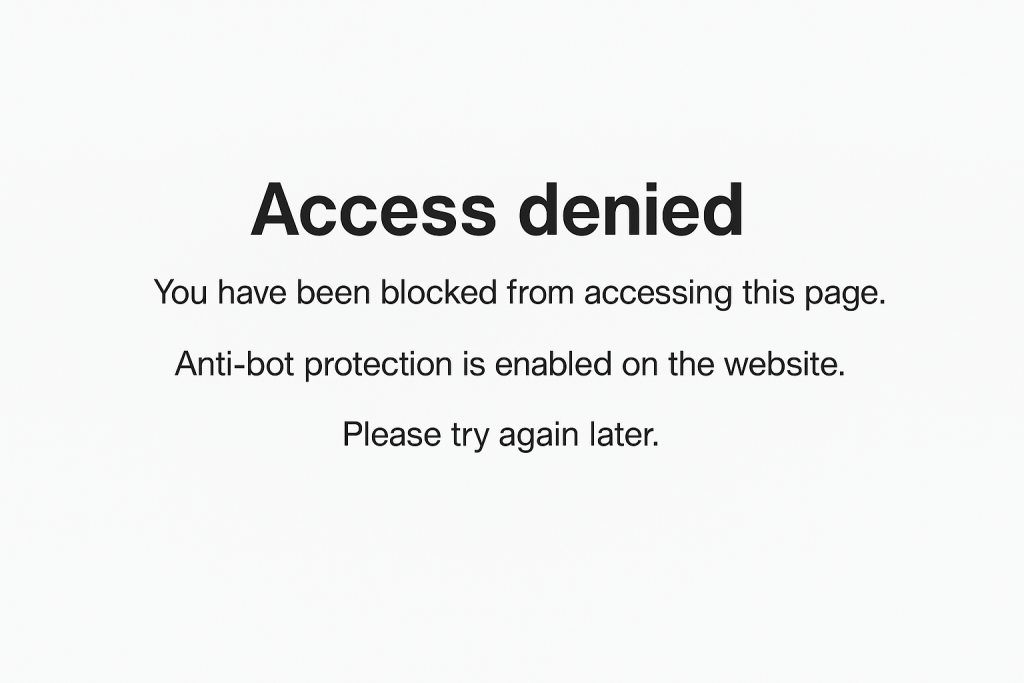
IP Address Blocking
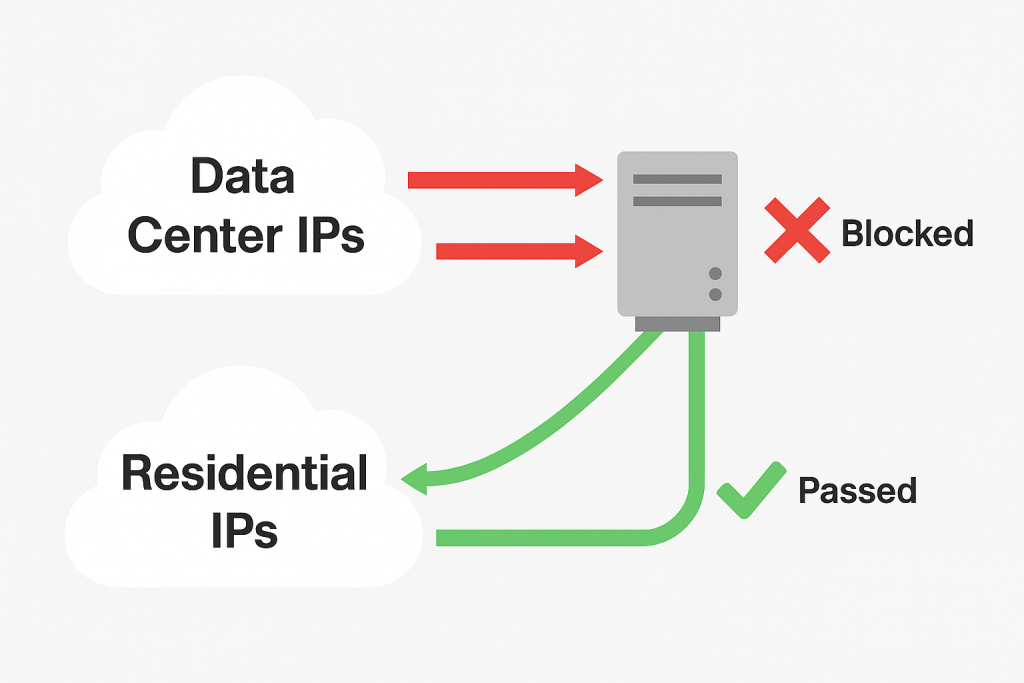
Many anti-scraping systems specifically target data center IP addresses, which are commonly used by scraping operations. When your script runs from a server or cloud instance, websites can easily identify and block these IP ranges. This forces you to consider residential IP solutions, proxy rotation, and other techniques to mask your scraping activity.
The API Alternative: URL to Text
Rather than building and maintaining this complex infrastructure yourself, web scraping APIs like URL to Text offer a more practical solution. These services handle all the technical challenges behind the scenes, allowing you to focus on your core application logic.
AI-Powered Content Extraction
URL to Text provides an “extract only main content with AI” feature that goes beyond simple HTML parsing. This AI-powered extraction identifies and returns only the primary content of a page, filtering out headers, footers, navigation menus, advertisements, and other irrelevant elements.
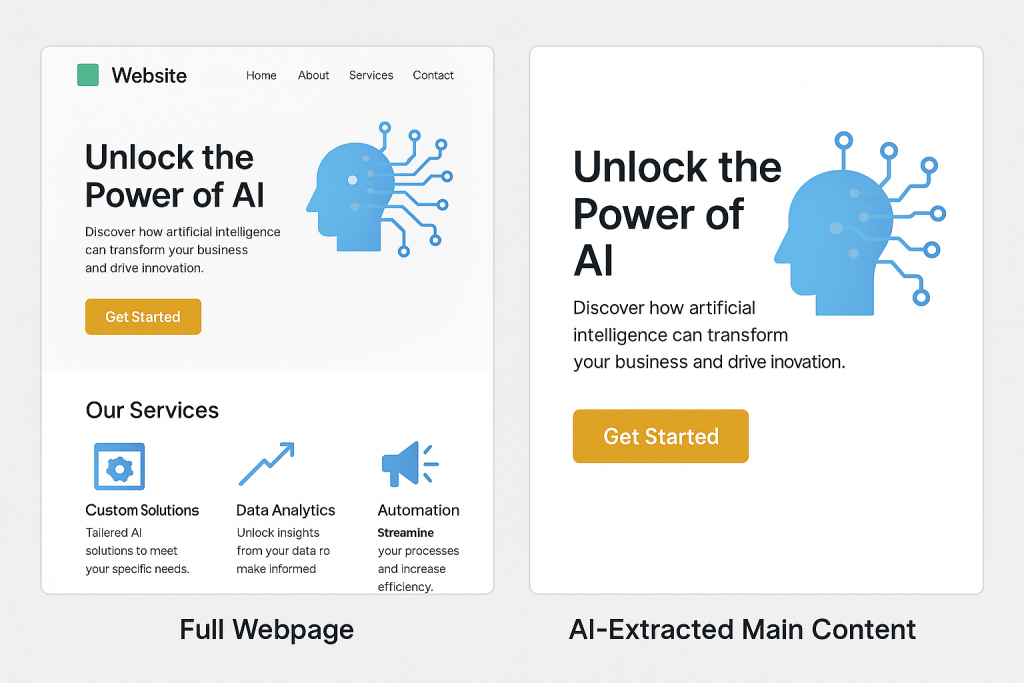
This intelligent extraction saves significant post-processing time and ensures you get clean, relevant data without manual filtering.
Built-in JavaScript Rendering
The API handles JavaScript rendering automatically, so you don’t need to manage headless browsers or worry about timing issues. Dynamic content loads properly, and you receive the fully rendered page content just as a human visitor would see it.
Residential IP Options
URL to Text offers residential IP routing options that help bypass data center IP blocks. This feature allows your requests to appear as if they’re coming from regular residential internet connections, significantly improving success rates against protected websites.
[Image placeholder: Screenshot of URL to Text dashboard showing residential IP selection option]
The Business Case for Using an API
Building and maintaining a robust web scraping infrastructure requires significant ongoing investment. You need to handle browser management, proxy rotation, anti-detection measures, infrastructure scaling, and constant updates as websites change their protection methods.
Web scraping APIs eliminate these operational burdens. Instead of spending engineering resources on scraping infrastructure, your team can focus on building your application’s core features and business logic. The API handles reliability, maintenance, and adaptation to new anti-scraping measures.
[Image placeholder: Diagram showing development time comparison between building custom scraper vs using API]
Getting Started
If you’re considering web scraping for your project, starting with an API service like URL to Text can save months of development time and ongoing maintenance headaches. You can explore the service and test its capabilities at urltotext.com, where you can try the platform for free and see how it handles the complex challenges of production web scraping.
The lesson here is clear: while web scraping starts simple, production requirements quickly reveal its true complexity. By leveraging specialized APIs, you can access powerful scraping capabilities without the technical overhead, allowing you to ship faster and focus on what matters most for your business.